우아한테크코스 테코톡
아코의 MySQL 아키텍처
카테고리 : 우아한테크코스 테코톡
https://youtu.be/w27fZGbtvZ0?si=-B7blD-tUw7dqoDC
아코의 MySQL 아키텍처
MySQL 서버의 흐름
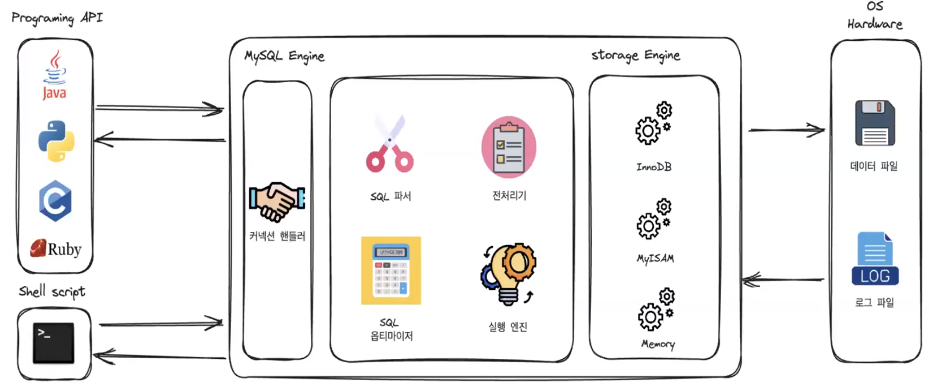
- 흔히 말하는 MySQL은 MySQL 서버이다
- MySQL 서버 내부는 MySQL 엔진과 스토리지 엔진으로 구분된다
- 사용자가 프로그램 api나 쉘 스크립트를 통해 MySQL 서버에 요청을 보내게 되면 MySQL 엔진 같은 경우에는 요청을 처리하는 역할을 하고 스토리지 엔진은 이 때 필요한 데이터를 하드웨어에서 가져오는 역할을 한다
MySQL 엔진 동작
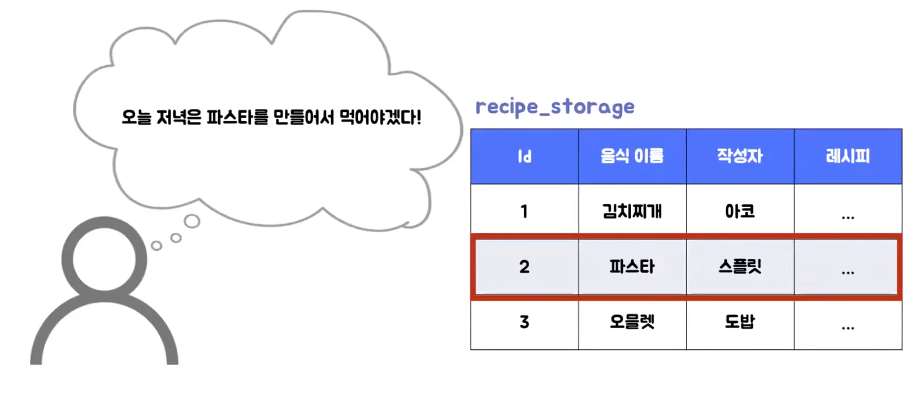
- 쿼리 파서 동작
- 쿼리 파서가 가장 먼저 동작하게 된다
- 쿼리 파서는 들어온 요청을 단어 단위의 토큰으로 분리를 한 뒤 문법적 오류를 체크 한다
- 문법적 오류가 없게 되면은 파서 트리 형태로 구성
- 쿼리 파서 및 전처리기 동작
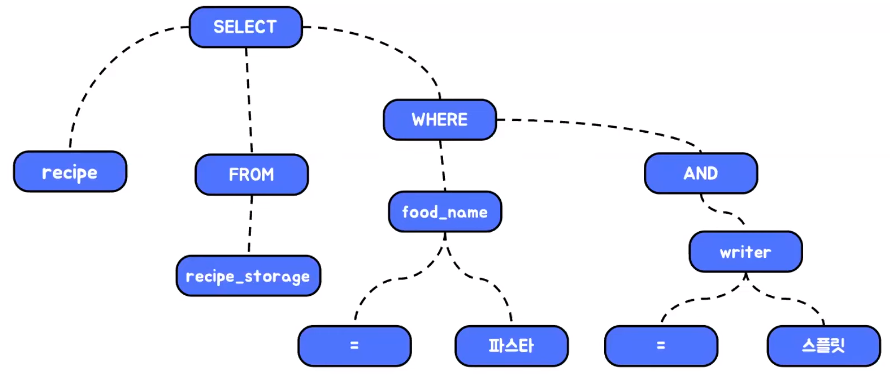
- 파서 트리 형태가 구성이 완료가 되면은 전처리기가 동작
- 전처리기 역시 논리적인 오류를 파악하는 것
- 예를 들면은 레시피 스토리지가 현재 실제로 존재하는 테이블인지 혹은 레시피라는 요리 레시피 테이블 안에 존재하는 것인지 사용자가 레시피 스토리지에 접근이 가능한지를 파악
- 옵티 마이저 동작
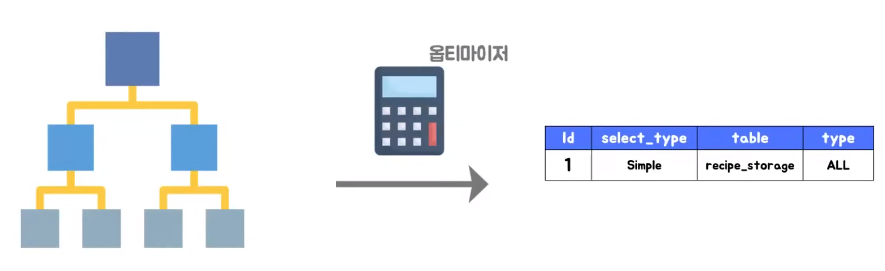
- 요소가 검증이 완료가 되면은 옵티마이저가 동작
- 옵티마이저는 최적화된 실행 계획을 생성해주는 역할을 한다
- 현재는 아무런 설정이 걸려 있지 않아 타입이 ALL로 나와 풀 스캔을 해서 데이터를 불러오는 형식으로 실행 계획을 세워줬지만 writer 열에다가 인덱스를 걸어 주게 되면 다른 실행 계획을 나타내 주는데 이때는 writer 인덱스를 통해 데이터를 조회하는 것을 알 수 있다

MySQL 엔진의 목적
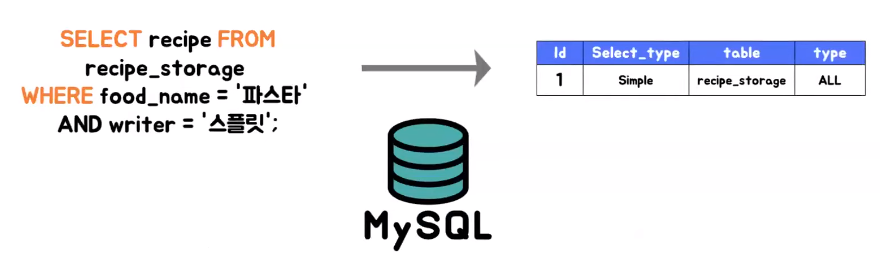
- MySQL의 목적은 요청 쿼리에 대해서 어떻게 실행 할지 결정을 하고 실행하는 역할이다
스토리지 엔진
- 스토리지 엔진은 디스크와 통신을 하며 사용자 요청에 따라 데이터를 불러오거나 가공하는 역할을 한다

- MySQL이 지원하는 스토리지 엔진은 여러 가지가 있는데 그 중에서도 InnoDB를 디폴트로 지원하고 있다
InnoDB 특징
버퍼 풀
- 버퍼 풀은 메인 메모리의 한 영역으로 테이블과 인덱스 데이터를 캐싱해두는 공간이다
- 즉 사용자 요청에 필요한 데이터가 버퍼 풀에 등재돼 있다면 디스크 I/O를 하지 않고 버퍼 풀에 등재된 내용을 사용자에게 전달해 준다
- 데이터 들은 페이지 단위로 데이터가 관리가 되는데 그 이유는 디스크의 데이터 저장 단위가 페이지 때문이다
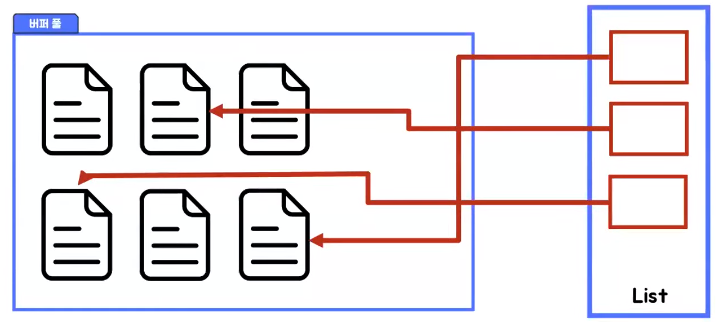
- 조회 과정에서 효율을 높이기 위해 페이지들은 링크드 리스트로 관리가 되는데 이 때 링크드 리스트는 LRU 알고리즘을 활용한다
LRU(Least Recent Used) 알고리즘
- LRU 알고리즘은 최신의 가장 최근에 가장 많이 안 사용된 데이터들이 탈락하는 알고리즘
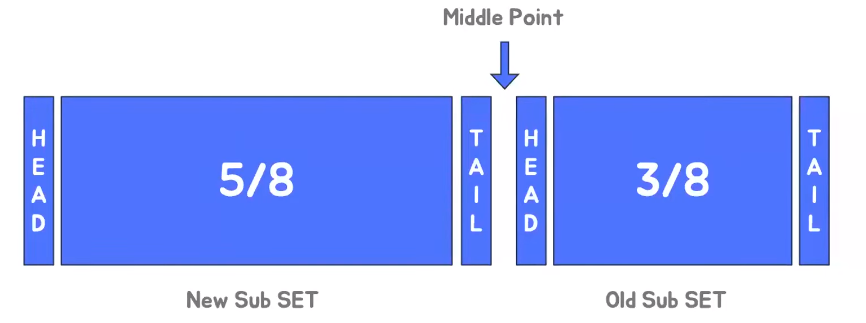
- New Sub SET, Old Sub SET, Middel Point가 있는데 New Sub SET은 링크드 리스트 에서 비교적 최근에 사용된 페이지들이 모인 공간 반면 Old Sub SET 같은 경우에는 비교적 덜 사용된 페이지들이 모인 공간 Middle Point는 New Sub SET과 Old Sub SET이 맞닿는 공간이다
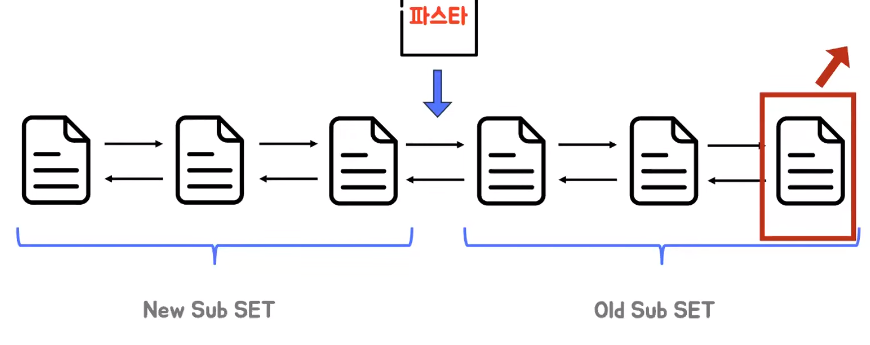
- 파스타 레시피 정보를 얻기 위해 요청이 들어왔다면 이 때 링크드 리스트에 파스타를 포함한 페이지가 존재하지 않는 상황에서는 Middle Point에 새로운 페이지가 들어오게 된다
- 이 때 리스트가 꽉 차 있다면 Old Sub SET의 꼬리부분에 있는 페이지가 탈락하게 된다
- Middle Point에 파스타 페이지가 들어오게 된 이유는 일시적으로 발생할 수 있는 요청으로 인해 기존에 자주 사용됐던 페이지들이 탈락하는 것을 막기 위해 New Sub SET의 헤드가 아닌 Middle Point로 들어오는 것이다
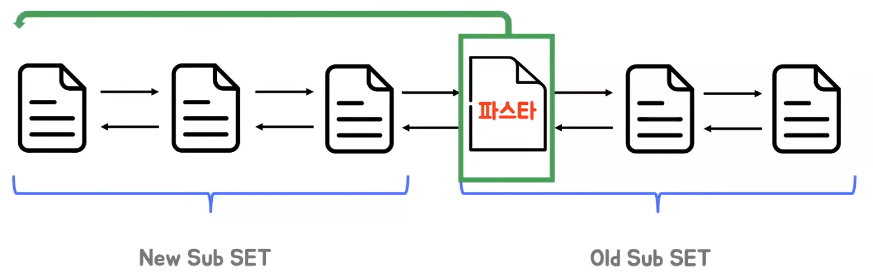
- 반대로 이미 링크드 리스트 포함되어 있다면 New Sub SET의 헤드로 이동하게 된다
- 버퍼 풀은 데이터를 캐싱을 해서 디스크 I/O 횟수를 줄일 뿐만 아니라 내부적으로 LRU 알고리즘을 통해 효과적으로 데이터를 읽는 데에 도움을 준다
InnoDB는 왜 MVCC를 지원하는가?
- 이전 MyISAM이 동작했던 방식
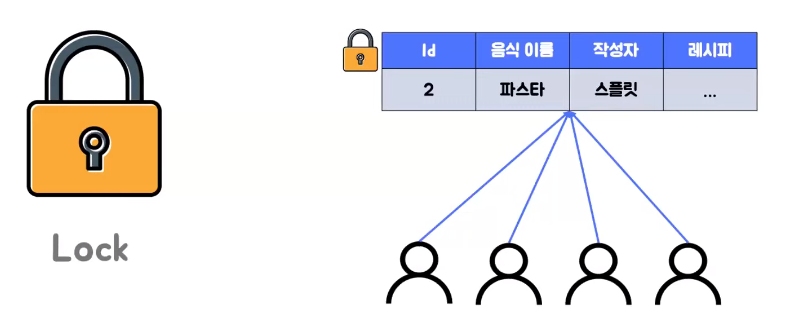
- MyISAM 같은 경우에는 락 기능을 통해서 동시성을 처리 했는데 이때는 큰 결함이 있었다
- 예를 들면 한 사용자가 파스타에 접근해서 락을 건 상태로 작업이 진행되고 있으면 다른 여러 사용자가 파스터의 데이터에 접근하려면 이 락이 풀릴 때까지 기다려야만 했다
- 즉 대량 요청에 따른 성능이 떨어진다는 문제점이 발생 했다
- 이런 문제점으로 인해 InnoDB는 MVCC를 지원하게 되었다
MVCC(Multi-Version Concurrency Control)
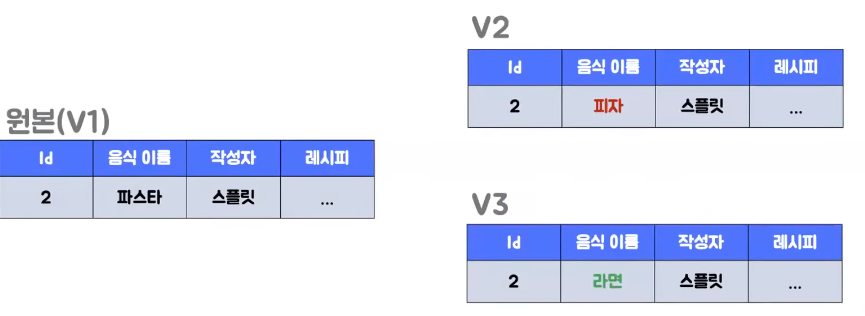
- MVCC는 Multi-Version Concurrency Control로 원본 데이터를 여러 버전으로 관리하여 동시성을 처리하는 기술
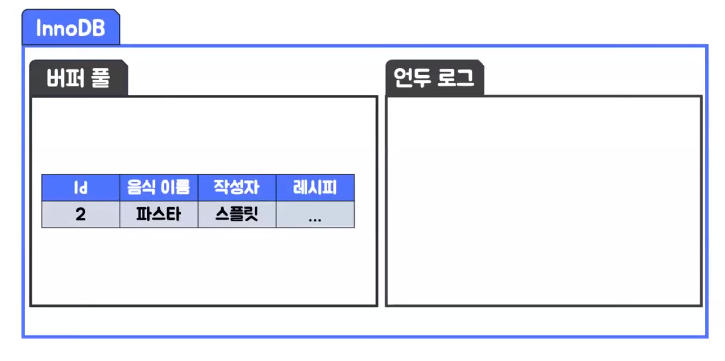
- InnoDB는 MVCC를 구현하기 위해서 언두 로그를 활용했다
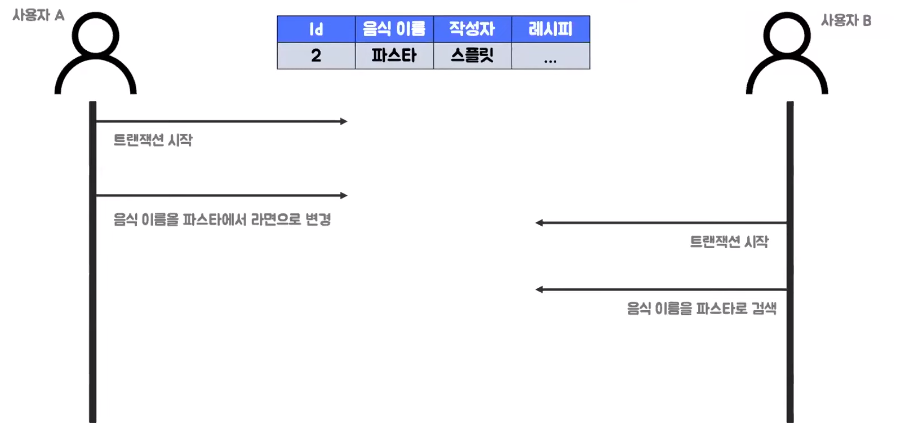
- 사용자 A와 사용자 B모두 파스타 데이터에 접근하려고 하는 상황인데 먼저 사용자 A가 트랜잭션을 시작하고 음식 이름을 파스타에서 라면으로 변경한면 버퍼 풀은 먼저 라면으로 데이터를 변경하게 되고 그 이전 버전의 데이터는 언두 로그로 이동 되게 된다
- 그 사용자의 끝나기 전에 사용자 B가 트랜잭션을 시작하고 음식 이름을 파스타로 검색을 하면 이때는 사용자B의 트랜잭션 격리 수준에 따라 다른 결과를 가져오게 된다
- 먼저 사용자 B의 트랜잭션 격리 수준이 read_uncommited면 버퍼 풀에 있는 정보를 불러 오기 때문에 파스타 데이터가 존재하지 않아 아무런 데이터 결과 값을 받지 못할 것이다
- 반면 사용자B의 트랜잭션의 격리수준이 read_commited와 repeatable_read라면 이때에는 언두 로그를 조회해서 파스타에 대한 레시피 정보를 받아올 수 있다
- 이처럼 MVCC는 여러 버전의 데이터를 관리하는 기술로 잠금이 걸려져 있더라도 읽기는 가능하도록 도와주는 기술이다
- 그리고 MySQL 같은 경우는 MVCC는 기본적으로 repeatable_read에서 활용된다