업무 프로세스 분석과 데이터베이스 모델링
물리적 데이터 모델링
카테고리 :
데이터베이스 모델링 tag #
Databasemodeling 물리적 데이터 모델링
물리적 데이터베이스 모델링에 대한 이해
물리적 데이터 모델링
| 논리적 데이터 모델링 | 물리적 데이터 모델링 |
|---|
| 특정 DBMS 제품을 고려하지 않고 관계형 데이터베이스 이론에 맞게 설정 | 특정 DBMS 제품 특성에 맞는 최적화된 데이터베이스 설계 |
물리적 데이터 모델링 작업 단계
- 개발 DBMS를 선정하고 컬럼의 데이터 타입과 사이즈를 정의한다
- 데이터 사용량 분석과 사용자들이 데이터 소스에 액세스 할 때의 구체적인 프로세스 분석
- 역정규화 수행
- 데이터베이스 내의 개체들 정의 (인덱스, 뷰)
- 물리적인 데이터베이스 생성
역정규화(De-Normalization)
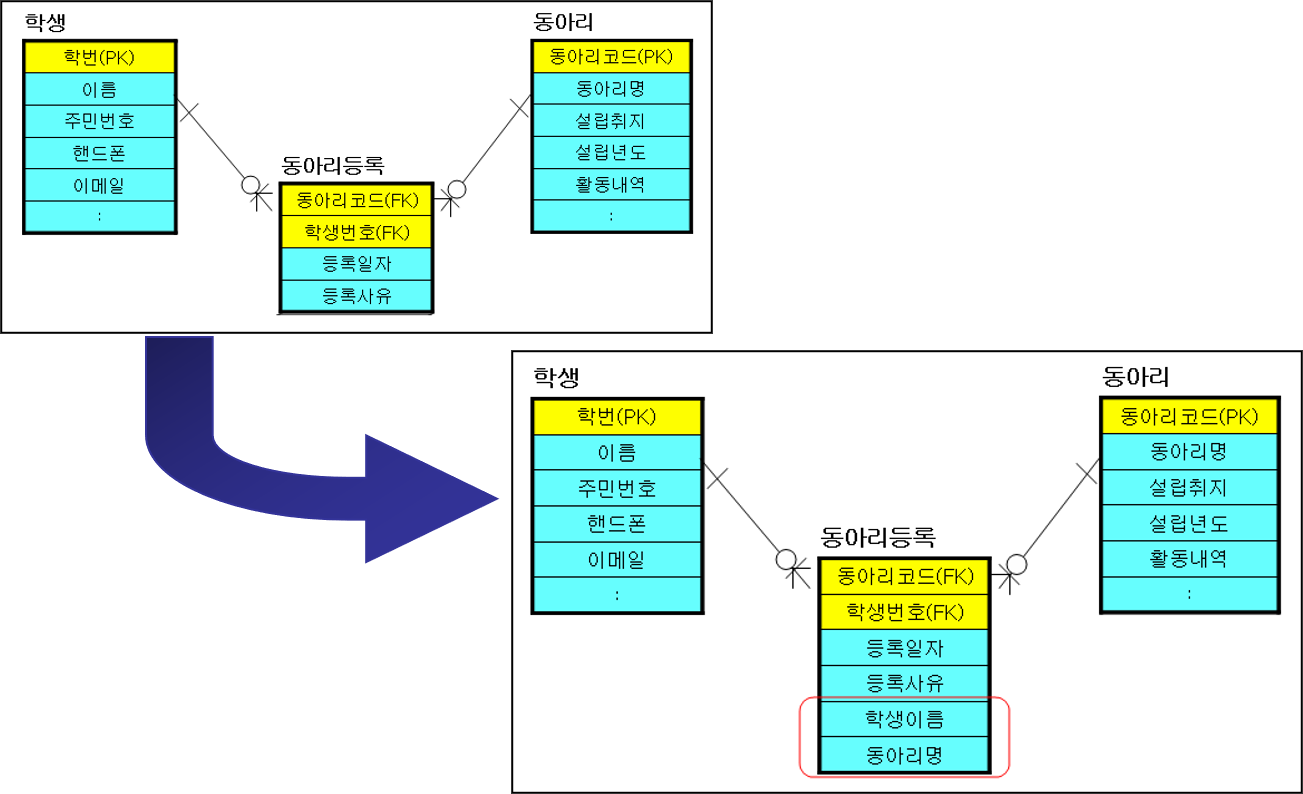
컬럼의 역정규화
파생 컬럼의 생성
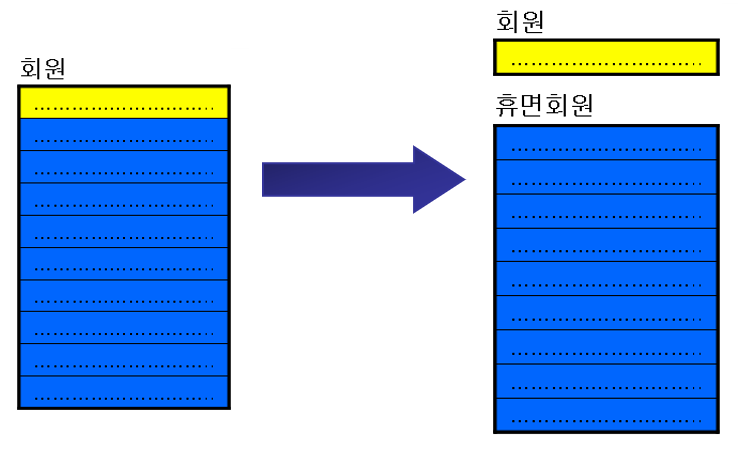
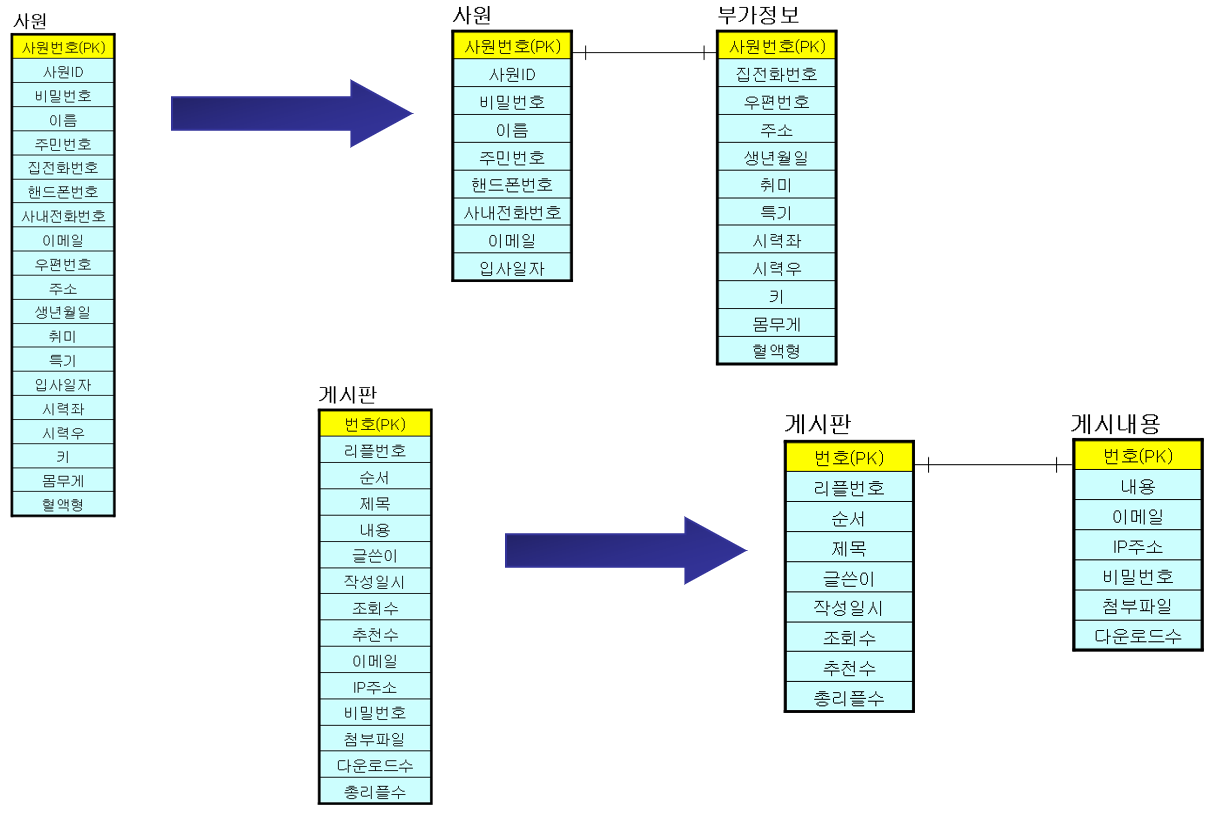
테이블 분리
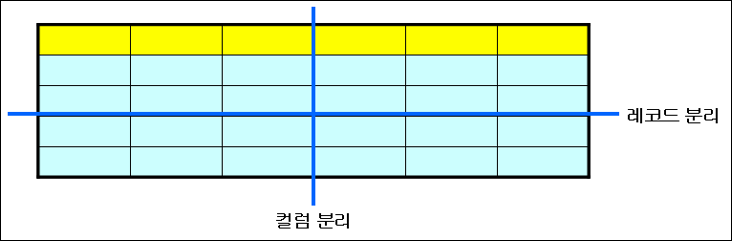
- 레코드 분리
- 컬럼 분리
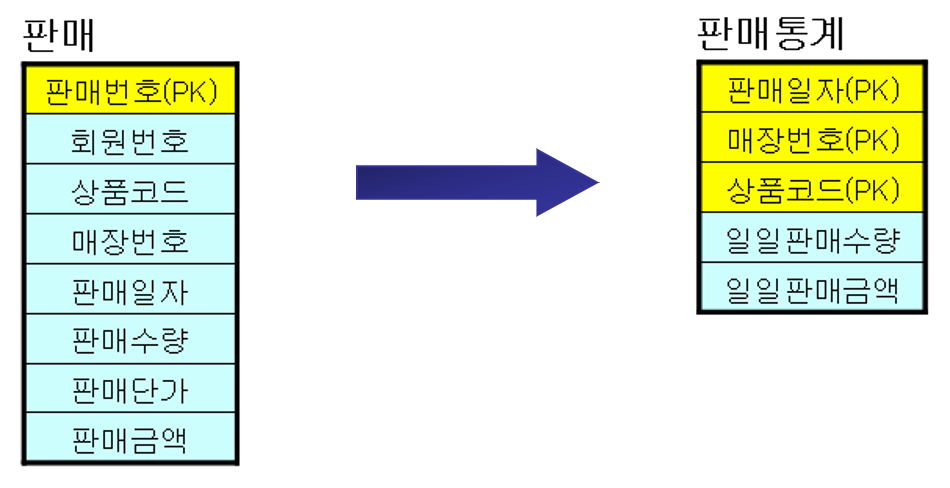
통계 테이블 생성
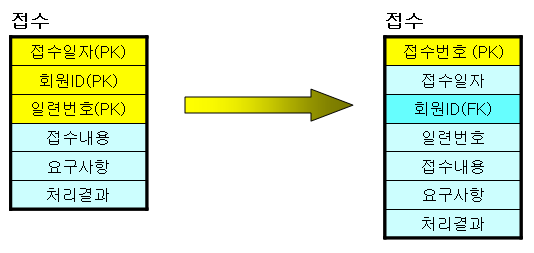
인공키(Surrogate key) 생성
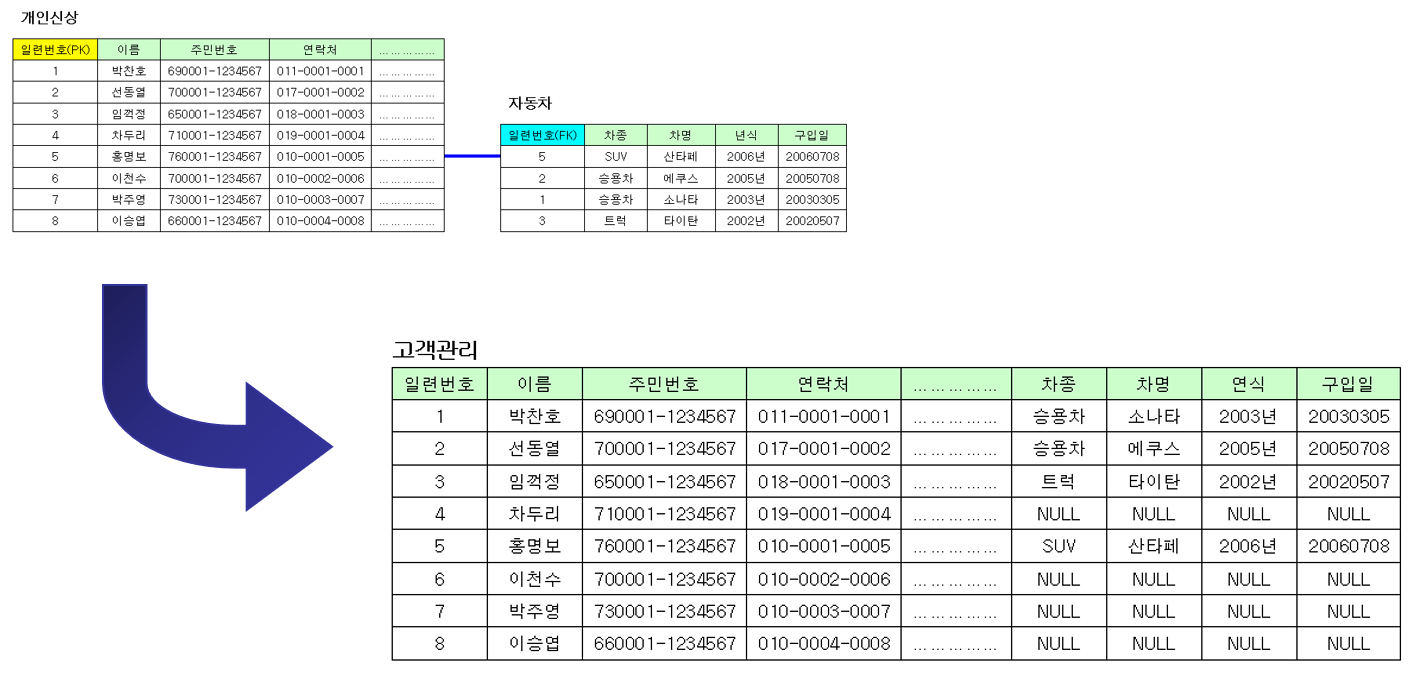
테이블 통합
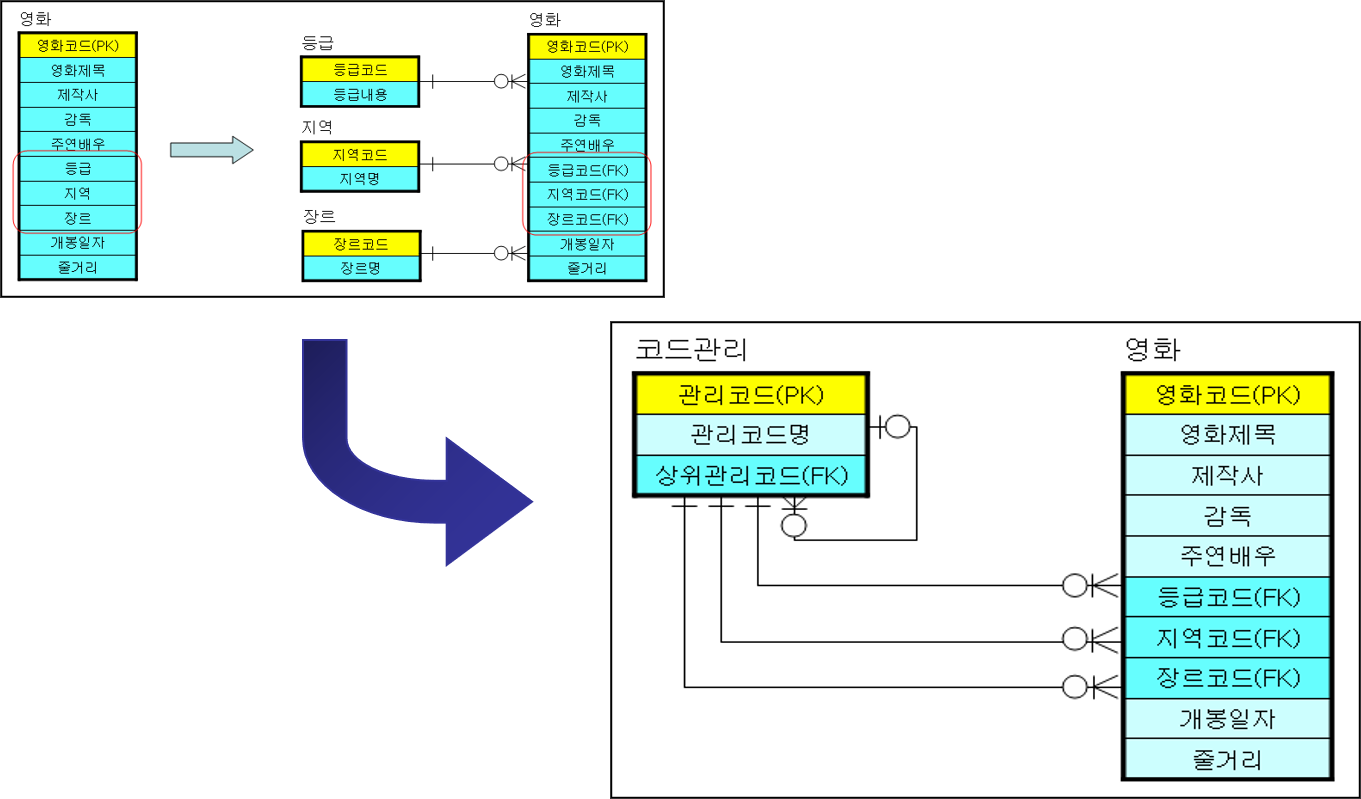
코드 테이블 관리
데이터베이스 내의 주요 개체 정의
뷰(View)의 정의
뷰를 사용하는 이유는?
- 편의성
- 보안성
- 성능향상
- 인덱스된 뷰 (Indexed View)
- 분할된 뷰 (Partitioned View)
저장 프로시저의 정의
- 저장 프로시저는 Transact-SQL 문장의 덩어리다
저장 프로시저의 장점
- 빠르다
- 파라미터를 사용할 수 있음으로 융통성이 뛰어나다
- 네트워크 트래픽을 줄여준다
- 데이터베이스의 복잡성을 줄여준다.
- 엄무 규칙을 여러 어플리케이션과 공유할 수 있다